
Bientôt nous vivrons dans un monde où les ordinateurs ne se contentent plus d’exécuter nos ordres, mais où ils deviennent des véritables scientifiques capables de faire leurs propres découvertes. C’est exactement ce que raconte ce papier fascinant intitulé « AlphaGo Moment for Model Architecture Discovery« , publié sur arXiv en juillet 2025 par une équipe de chercheurs de l’Université Jiao Tong de Shanghai et du Shanghai AI Laboratory. Pensez à AlphaGo, ce programme qui a battu le champion du monde du Go en faisant un coup génial appelé « Move 37 », un mouvement que personne n’avait jamais imaginé. Eh bien, ici, les chercheurs ont créé un système d’intelligence artificielle qui fait la même chose, mais pour inventer de nouveaux types de cerveaux d’IA encore plus intelligents !
Tout commence par un gros problème dans le monde de l’IA. Aujourd’hui, les ordinateurs sont de plus en plus puissants, mais les humains qui les conçoivent restent limités par leur temps et leur imagination. Concevoir une nouvelle « architecture » (voit ça comme la forme ou la recette d’un cerveau artificiel) prend des mois à des experts. Résultat : le progrès de l’IA dépend trop des humains, pas assez des ordinateurs. Les auteurs du papier disent que c’est un énorme frein, comme si on demandait à des singes de construire des fusées au lieu d’utiliser des robots. Leur solution s’appelle ASI-ARCH, un acronyme pour « Artificial Superintelligence for AI Research ». C’est la première fois qu’une IA fait tout un travail de recherche scientifique toute seule : elle invente des idées, écrit du code, teste, analyse les résultats et s’améliore. En gros, c’est une usine à cerveaux d’IA automatisée !
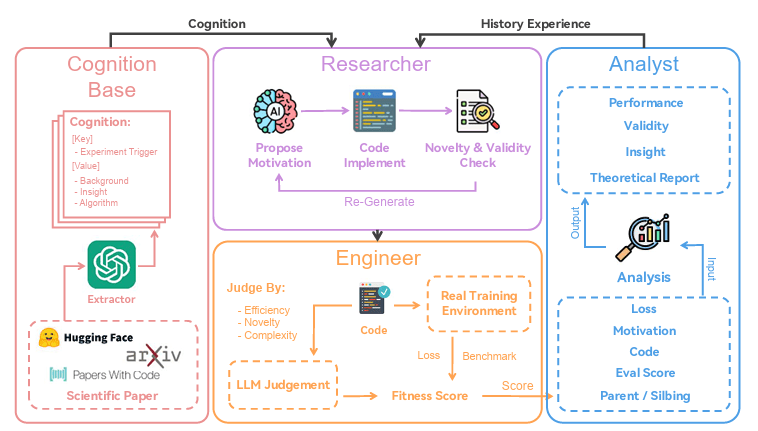
Pour comprendre comment ça marche, imagine une petite équipe de robots dans un laboratoire. ASI-ARCH est divisée en trois rôles principaux qui travaillent ensemble en boucle fermée, comme un cycle sans fin qui s’améliore à chaque tour. D’abord, il y a le « Researcher« , le chercheur créatif. Il lit toutes les expériences passées, stockées dans une grande base de données, mais aussi le trésor de connaissances humaines extraites de 100 papiers célèbres sur les « attentions linéaires » – un type de mécanisme qui permet aux IA de traiter des textes longs sans exploser en calculs, contrairement aux Transformers classiques. Avec ces infos, le Researcher propose une nouvelle architecture : il explique pourquoi cette idée est bonne, puis écrit le code complet pour la réaliser. Pour éviter de répéter les mêmes idées, il y a un contrôle de « similarité » qui vérifie si c’est vraiment nouveau, et un test pour s’assurer que le code ne plante pas.
Ensuite vient l' »Engineer« , l’ingénieur pratique. Il prend ce code, le lance dans un environnement réel d’entraînement sur des données massives, et surveille tout. Si ça bugge ou si c’est trop lent – par exemple, si l’entraînement prend deux fois plus de temps que prévu –, l’Engineer analyse les erreurs et corrige le code tout seul, sans abandonner l’idée. C’est super important, car les anciennes méthodes jetaient les idées prometteuses juste à cause d’un petit bug de programmation. Une fois l’entraînement fini, une autre IA-juge donne une note qualitative : est-ce que l’architecture est élégante, efficace, innovante ? Tout ça forme un score, une note globale qui mélange les performances mesurées (comme la perte d’erreur ou les scores sur des tests de compréhension de texte) et cette évaluation subjective. La formule est simple : on prend les améliorations par rapport à un modèle de base (DeltaNet), on les transforme avec une fonction mathématique appelée sigmoïde pour bien valoriser les petits progrès, et on moyenne le tout. Ça empêche l’IA de tricher en optimisant seulement les chiffres sans vrai génie.
Enfin, l' »Analyst« , l’analyste malin, entre en scène. Il regarde les résultats de l’expérience, compare avec les « parents » et « frères » de l’architecture dans un arbre généalogique des modèles (imagine un arbre où chaque branche est une mutation d’un modèle précédent), et écrit un rapport : qu’est-ce qui a marché, pourquoi ça a échoué, quelles leçons en tirer ? Ces analyses rejoignent la base de données, enrichies par les connaissances humaines, la « Cognition Base » (papiers scientifiques, Hugging Face …). Tout se passe en deux étapes pour économiser les ordinateurs puissants (surtout les GPU) : d’abord une exploration large avec des petits modèles de 20 millions de paramètres sur 1 milliard de mots, pour tester des milliers d’idées en 10 000 heures de calcul. Puis, on garde les 1350 meilleures, on les agrandit à 340 millions de paramètres, et on valide la crème de la crème sur des entraînements plus longs. Au final, après 20 000 heures de GPU, ASI-ARCH a découvert 106 architectures state-of-the-art, cinq d’entre elles étant testées exhaustivement sur 15 milliards de tokens.
Et les résultats ? Incroyables ! Sur des benchmarks comme ARC (raisonnement), BoolQ (questions-réponses) ou HellaSwag (bons sens), ces nouvelles architectures battent DeltaNet, Gated DeltaNet et même Mamba2, des champions humains. Prends l’architecture PathGateFusionNet : elle crée un « routeur hiérarchique » qui décide intelligemment si l’info locale ou globale est prioritaire, avec des connexions résiduelles pour que l’apprentissage soit stable. ContentSharpRouter rend les décisions de routage « tranchantes » mais adaptées au contenu, grâce à une température apprise. FusionGatedFIRNet utilise des sigmoïdes indépendants au lieu d’un softmax, pour activer plusieurs chemins à la fois. HierGateNet ajoute des « planchers dynamiques » pour que les voies importantes ne se ferment jamais complètement. Et AdaMultiPathGateNet contrôle tout au niveau de chaque mot, avec des pénalités d’entropie pour la diversité. Dans les tableaux, on voit des baisses de perte de 0,1 à 0,2 points et des gains de scores moyens de 1 à 3 points – pas énorme, mais significatif dans ce domaine précis des attentions linéaires, où les progrès sont rares.
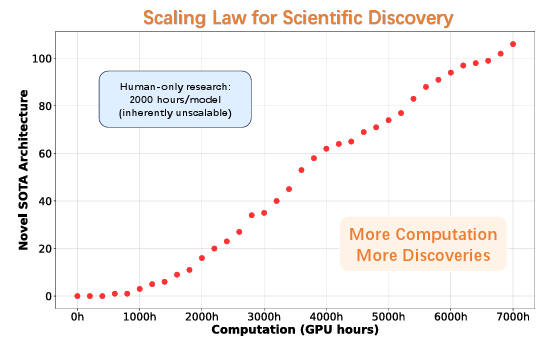
Le clou du spectacle, c’est la « loi d’échelle pour la découverte scientifique ». En traçant le nombre d’architectures sympa en rapport aux heures de calcul, on obtient une droite parfaite : plus de puissance de calcul = plus de découvertes géniales. Les humains ? Limités à 2000 heures par modèle, sans scalabilité. L’IA ? Illimitée, scalable comme une fusée. C’est la preuve que la recherche peut passer d’un processus humain lent à un processus rapide. Les chercheurs analysent même les motifs émergents : beaucoup d’idées viennent des analyses internes de l’IA, pas juste des copies humaines, montrant une vraie « intelligence de design » nouvelle.
ASI-ARCH n’est pas parfait – il se limite aux attentions linéaires pour tester, et dépend encore un peu d’humains pour le cadre global. Mais c’est un blueprint pour l’avenir : des IA qui s’améliorent seules, accélérant le progrès vers une superintelligence. Tout est open-source : le code, les 106 modèles, les traces cognitives. Pour la science, c’est comme si AlphaGo avait non seulement gagné au Go, mais appris à inventer de nouveaux jeux encore plus durs. Demain, imagine des ASI-ARCH pour la médecine, la physique… Le futur de la découverte humaine pourrait bien être automatique !
Lire aussi : IA et éducation, l’évolution silencieuse en marche





