
Il y a des mises à jour qui sentent le petit ajustement de façade, et d’autres qui ressemblent à un vrai changement de tempo. Stable Audio 3.0 appartient clairement à la deuxième catégorie. Stability AI ne se contente plus de faire “du son par IA”, elle pousse une famille de modèles audio pensée pour l’expérimentation artistique, la génération variable, l’édition et les déploiements concrets, avec plusieurs variantes. Dans cet article, on va décortiquer ce que change Stable Audio 3.0 par rapport aux versions précédentes, pourquoi son architecture intéresse autant les musiciens que les sound designers, ce que signifie réellement “open weights” dans ce contexte, comment l’intégration dans ComfyUI accélère son adoption, et où se situent encore les limites, notamment sur le plan de la disponibilité, des droits et de l’usage professionnel.
Ce que Stable Audio 3.0 apporte vraiment
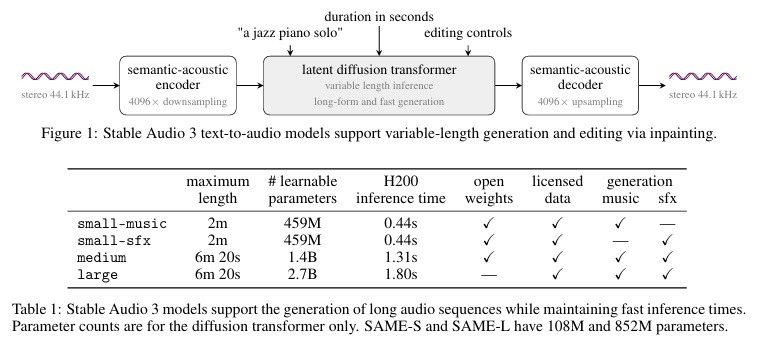
Stable Audio 3.0 n’est pas un simple rafraîchissement de surface. Stability AI le présente comme une famille de modèles conçue pour produire de la musique et des effets sonores à durée variable, avec une structure musicale plus solide sur les formats longs. Le point le plus marquant, c’est la capacité à générer des séquences allant jusqu’à environ six minutes vingt pour les modèles Medium et Large, alors que les anciennes générations ouvertes étaient bien plus limitées en durée. Pour les créateurs audio, ça change tout, parce qu’un outil qui sait seulement faire un jingle de quelques secondes ne joue pas dans la même cour qu’un modèle capable de tenir une vraie progression musicale.
Autre évolution importante, la génération n’est plus pensée comme un simple “prompt → fichier audio”, mais comme un système plus souple. Capable, par exemple, de travailler sur des clips de longueur variable, avec des usages allant du sound effect rapide à la composition instrumentale plus développée. Stability insiste aussi sur le fait que les modèles ont été entraînés sur des données entièrement licenciées, ce qui constitue un argument central dans un domaine où la provenance des données est devenue presque aussi importante que la qualité du rendu final. C’est un détail qui n’en est pas un car dans la musique générative, le droit d’auteur n’est jamais bien loin du pavé numérique.
Une famille de modèles, pas un seul produit
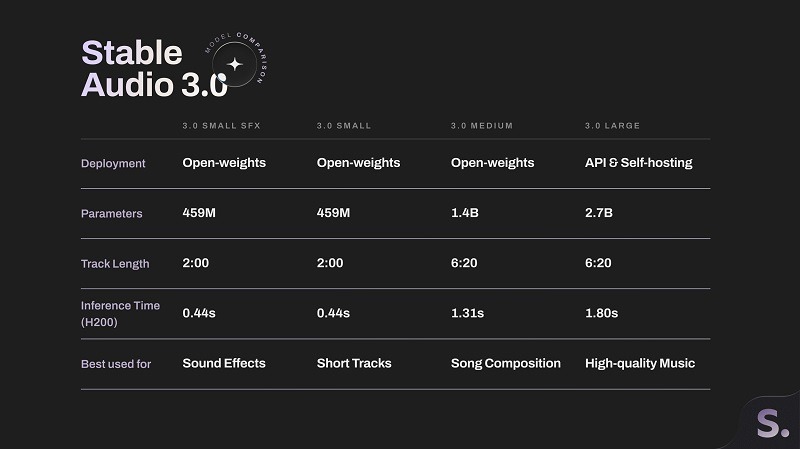
Le lancement Stable Audio 3.0 repose sur plusieurs variantes : Small SFX, Small Music, Medium et Large. Les deux modèles Small sont conçus pour des clips courts (jusqu’à environ 2 minutes) avec un profil léger qui peut même tourner sur CPU dans certains workflows. Le modèle Medium monte jusqu’à environ six minutes vingt, avec un équilibre plus intéressant entre longueur, structure et accessibilité matérielle.
Le modèle Large, lui, vise le haut de gamme avec une meilleure musicalité, génération plus propre, usage via API ou auto-hébergement pour les entreprises. Stability AI le réserve donc aux déploiements où la qualité, la latence et le contrôle d’infrastructure comptent vraiment. Cette segmentation est plutôt intelligente, car elle évite de forcer tout le monde à consommer un monstre de calcul pour générer un simple fond sonore. Dans les faits, cela permet à la fois des usages légers pour les indépendants et des intégrations sérieuses pour des éditeurs, studios ou plateformes. Lien vers l’étude complète.
Pourquoi le modèle intéresse autant les créateurs audio
Le premier intérêt de Stable Audio 3.0, c’est la possibilité de générer du son long et structuré sans devoir découper tout le processus en micro-bouts assemblés à la main. Pour un compositeur, cela veut dire plus de continuité harmonique, des transitions mieux tenues, et moins d’effet “boucle sympa mais incapable de raconter une histoire”. Pour un sound designer, cela signifie des effets, des ambiances et des textures plus riches à intégrer dans une vidéo, une pub, un jeu ou une interface.
Le deuxième intérêt, c’est la dimension éditable. L’article de recherche sur Stable Audio 3 souligne une logique d’édition et de génération variable, avec des modèles rapides pensés pour aller au-delà du simple échantillon sonore. Dans ComfyUI, ce point devient très concret. Les workflows “day-0 support” permettent déjà d’enchaîner prompt, durée, génération et intégration dans un pipeline visuel ou audio plus large. Pour un créatif qui travaille déjà dans un environnement nodal, c’est une porte d’entrée confortable vers des prototypes rapides.
Le troisième intérêt, c’est l’ouverture. Les modèles Small et Medium sont disponibles en open weights sur Hugging Face, ce qui facilite les tests, l’expérimentation locale et certaines intégrations sans dépendre d’un service totalement fermé. C’est exactement le type de détail qui fait la différence entre une démo sympathique et un outil qui peut vraiment s’insérer dans un atelier de production.
Comment l’écosystème s’organise
Le support “day-0” de ComfyUI est révélateur car dès la sortie, l’écosystème s’est empressé de brancher Stable Audio 3.0 à des workflows existants pour la génération de sound effects, de loops et de morceaux plus complets. Ce qui montre que le modèle n’est pas pensé comme un gadget isolé, mais comme une brique intégrable dans une chaîne créative déjà mature. Quand un modèle devient utilisable dans ComfyUI presque immédiatement, il entre dans la vraie vie des créateurs plus vite que les annonces marketing ne le laissent parfois croire.
Les discussions techniques autour du lancement montrent aussi un engouement très concret côté communauté, avec des tests rapides, des résultats partagés et une curiosité forte autour de la qualité de structure musicale obtenue. Un modèle audio ne vit pas seulement dans les slides de lancement, il vit dans les essais, les comparaisons et les exports WAV que les utilisateurs font réellement.
Dans une logique de production, Stable Audio 3.0 se place à mi-chemin entre le générateur d’idées et l’outil de préproduction avancé. Il peut servir à générer une base musicale, des ambiances, des motifs rythmiques ou des textures à développer ensuite dans un DAW. Pour les créateurs de contenus, cela peut accélérer la fabrique de musiques d’habillage, d’illustrations sonores ou de maquettes destinées à des clients.
Pour les utilisateurs qui produisent déjà de la musique assistée par IA, le vrai intérêt est ailleurs. Stable Audio 3.0 permet de monter en durée sans sacrifier complètement la cohérence. C’est le point qui le différencie d’une foule d’outils capables de sortir un beau son pendant dix secondes puis de s’effondrer au-delà. Si vous voulez aller plus loin sur ce terrain, l’article les meilleurs générateurs de musique IA permet de comparer les solutions du marché.
Ce qu’il faut surveiller avant de l’adopter
La première question à poser concerne les droits et le cadre d’usage. Stability AI met en avant des données pleinement licenciées, ce qui est rassurant, mais il reste essentiel de vérifier les conditions de licence du modèle choisi, surtout pour les usages commerciaux et les grandes structures. Le modèle Large n’est pas librement distribué comme les versions open weights, ce qui introduit une frontière nette entre expérimentation ouverte et usage professionnel plus encadré.
La deuxième question concerne la qualité selon le contexte. Comme souvent avec les générateurs audio, plus le besoin est précis, plus l’outil doit être piloté finement. Si vous cherchez une identité sonore ultra spécifique, un morceau vocal très précis ou une synchro millimétrée avec des images, il faudra probablement compléter Stable Audio par de la composition, du montage ou de l’édition manuelle. Le modèle aide beaucoup, il ne remplace pas un directeur artistique.
Enfin, il faut garder un œil sur l’écosystème matériel. Les modèles Small sont nettement plus accessibles, tandis que les versions Medium et surtout Large demandent plus de ressources, ce qui conditionne forcément l’adoption selon le profil utilisateur. Dans un studio léger ou chez un créateur indépendant, ce n’est pas négligeable. Pour comprendre l’impact plus large de cette accélération sur les métiers créatifs, vous pouvez lire impact de l’IA sur l’industrie musicale.
Pourquoi cette mise à jour compte pour les créateurs
Stable Audio 3.0 n’est pas seulement une nouvelle version. C’est une tentative de faire basculer l’audio génératif du stade du brouillon sonore vers celui d’un véritable outil de création structurée. Le fait d’avoir des modèles open weights, des durées plus longues, une meilleure cohérence musicale et une intégration rapide dans les outils de production lui donne une crédibilité que beaucoup d’outils audio IA n’atteignent jamais.
Si vous travaillez déjà avec des voix, des workflows hybrides ou des contenus musicaux, le complément logique est que votre voix devient un instrument.



")

